Imagine you're a project manager tasked with launching a new marketing campaign. Obviously, you need customer data. At least a general one: demographics, purchase history, and website behavior.
But here's the catch: the data you need resides across different departments: marketing automation software, a customer relationship management (CRM) system, and a separate web analytics platform. This fragmented approach to operations data management often leads to miscommunication, data inconsistencies, and slow decision-making.
Extracting, cleaning, and unifying this data becomes a time-consuming manual effort, delaying your campaign launch and hindering your ability to make a splash.
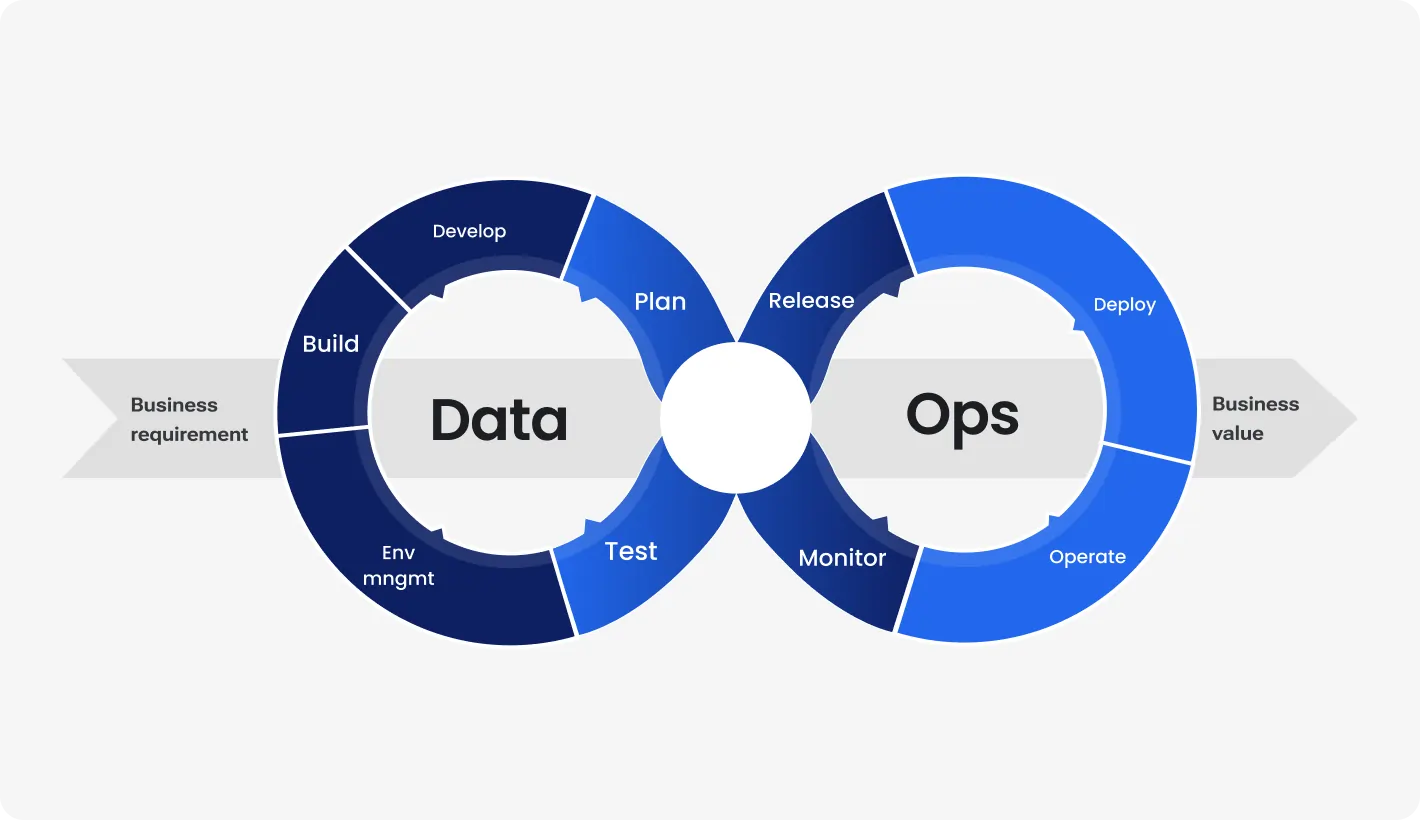
Enter DataOps. It is a new approach to data management with much more to say about collaboration and agility. It integrates the practices of DevOps with data management to create a more streamlined and efficient process.
The DataOps methodology emphasizes automation, monitoring, and collaboration to ensure data quality and reliability. It aims to improve the flow of data across the company, making it easier to access (according to access level though) and analyze. As a consequence — faster insights, better decision-making, and a more agile response to business needs.
Let’s explore the DataOps definition and the core principles of such an approach.
Demystifying data management pain points
Traditional data management approaches are often hare-brained, which can hinder a business's ability to use data properly. Any business wants to be at the top of the competitive curve. This requires timely or even real-time access to data to support data-driven decision-making, which is utterly essential for the increasing use of artificial intelligence (AI).
Simultaneously, today's data operations are larger (in volume), faster (in velocity), and more diverse (in variety) than ever before. Data comes from sources both inside and outside the organization, residing in the cloud and on-premises, within both modern and legacy systems. Data infrastructure and technologies, such as cloud, mobile, edge computing, and AI, are constantly advancing.
Achieve efficiency through data transformation
Among the mentioned ones, there are some more pain points.
Silos between data teams
Data teams (data engineers, data scientists, and data analysts) often operate in isolation. Many studies, including Forrester's, reveal that over half of surveyed data professionals report challenges collaborating across different data teams. This separation leads to inefficiencies and communication gaps.
Inconsistent data pipelines and manual processes
Fragmented data sources and manual processes for data extraction, transformation, and loading (ETL) create significant challenges. Manual data handling increases the risk of errors and makes it difficult to ensure data quality and reliability.
Inconsistent pipelines can lead to data discrepancies, making it hard to trust the insights derived from them. This is not to mention the time-consuming characteristic of the manual processes and their prone to human error.
Slow delivery of insights
What do you need data for, if it doesn’t lead to business insights and, hence, profit? The main roadblock in quick and effective data interpretation lies in complex and cumbersome data workflows.
Traditional data management methods often involve multiple steps and handoffs, slowing down the entire process. This delay means that decision-makers do not get timely insights, which can hinder their ability to respond to market changes or operational issues promptly. For example, AWS Business Insights revealed that a mind-blowing 97% (!) of businesses struggle is unused in companies.
Adding insult to injury, 74% of employees report feeling overwhelmed or unhappy when working with data. Unhappy workers, flawed insights.
On the way to addressing challenges
Eliminate silos: Promote cross-functional teams and shared tools to enhance collaboration and communication.
Automate data pipelines: Implement automated tools and standardized processes to maintain data quality and consistency.
Streamline workflows: Simplify data workflows to reduce complexity and speed up the delivery of insights.
These challenges collectively bring about a frustrating data management experience for all involved. DataOps fosters collaboration, streamlines processes, and ultimately enables faster delivery of valuable insights.
Introducing DataOps: A collaborative approach
What are data operations?
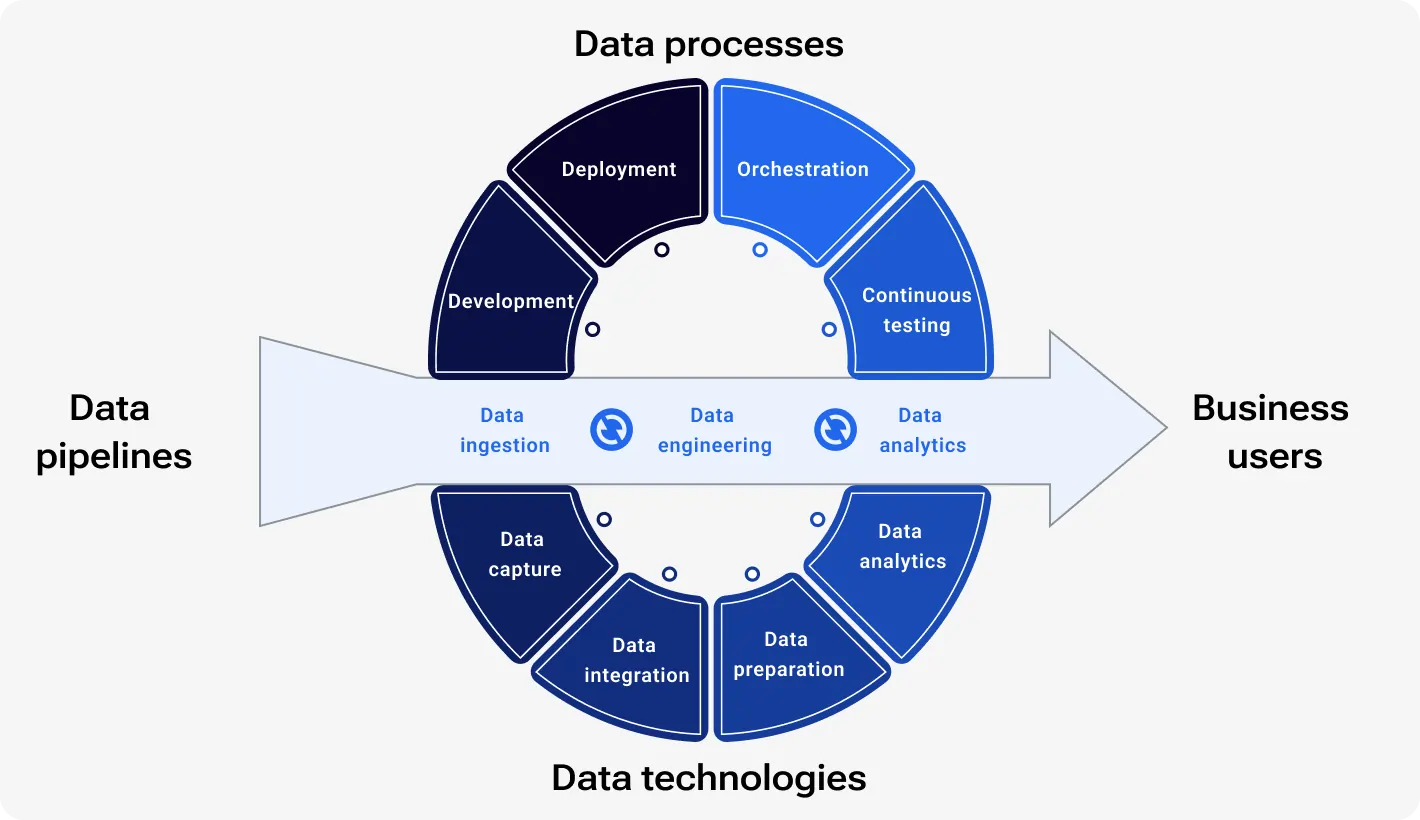
DataOps is a set of practices and principles that mimic data management processes as software development processes.
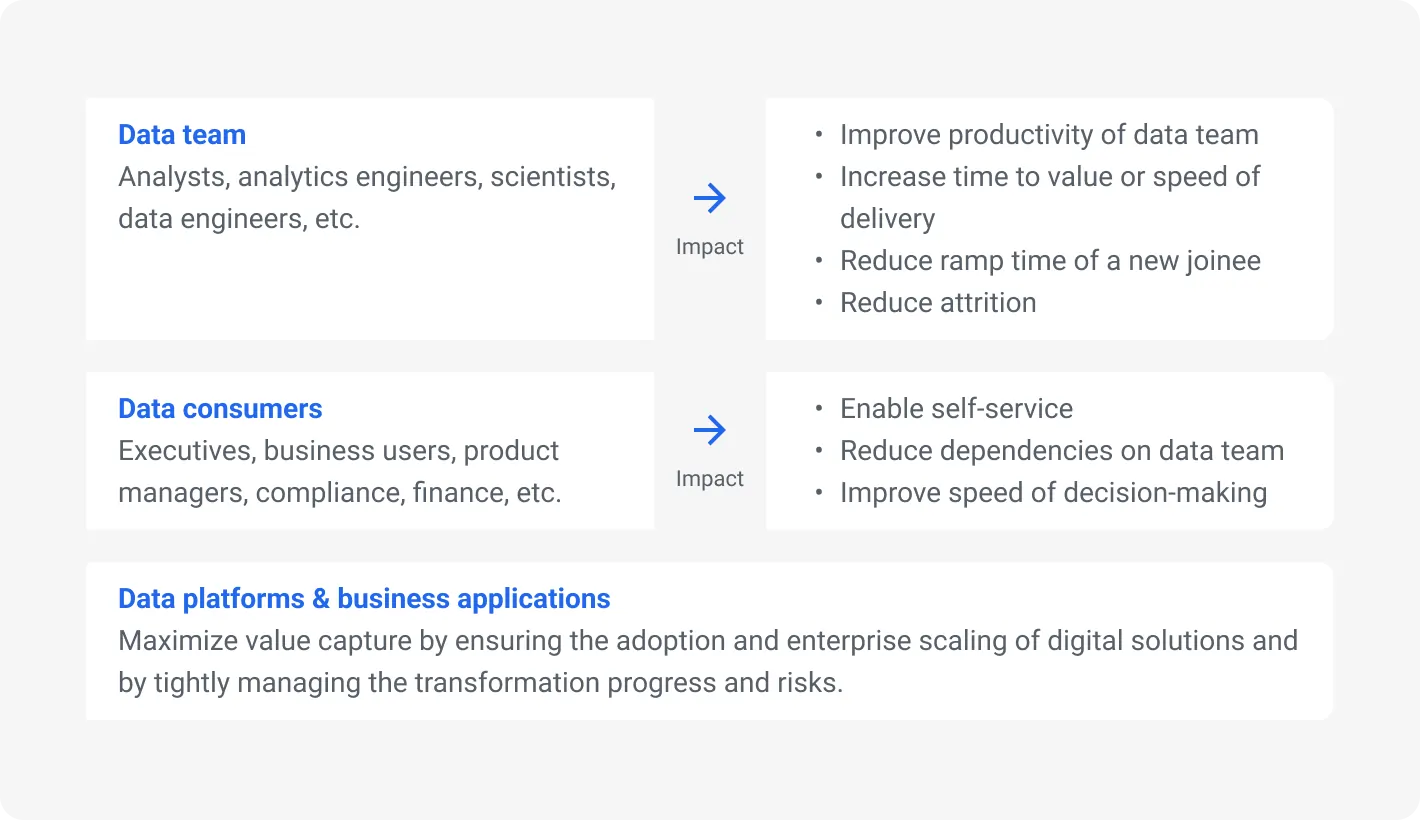
Operations data management automates and improves the flow of data across the entire lifecycle. It aims to enhance collaboration among data teams – engineering, science, and analytics – by breaking down silos and promoting efficient data management. DataOps ensures data quality, accelerates delivery, and fosters a collaborative environment.
Promoting collaboration between data teams
As we already said this approach promotes collaboration by integrating processes and tools that enable seamless communication and data sharing between different data specialists. It breaks down the traditional gaps that hinder efficiency and innovation.
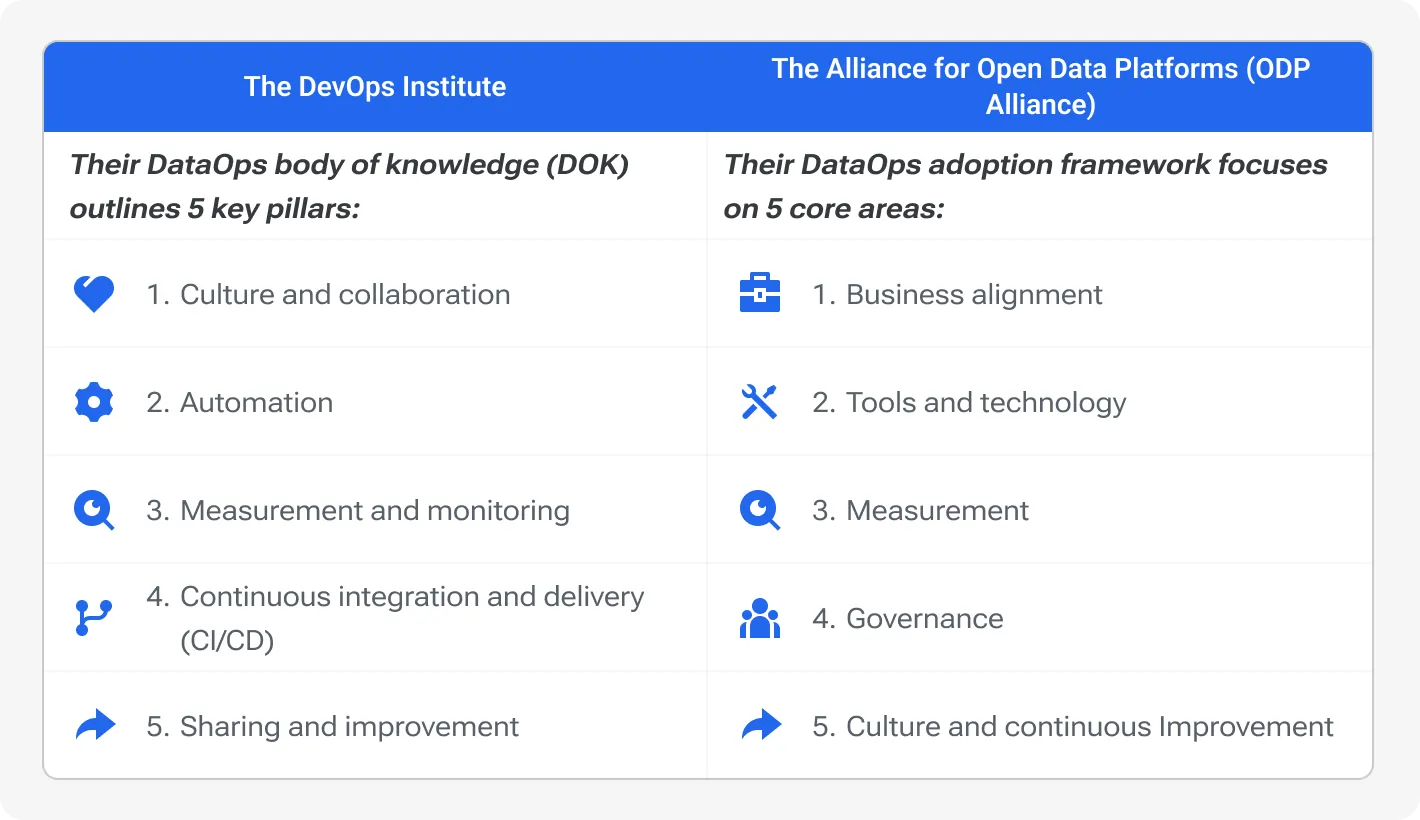
Two common frameworks for DataOps that are widely recognized:
1. Gartner’s DataOps Framework: Gartner emphasizes the importance of agile methodologies, DevOps principles, and a focus on data quality and governance. Their framework outlines key practices for improving data pipeline automation and enhancing collaboration across teams.
2. DataOps manifesto: The framework, described in Manifesto, developed by industry experts. It outlines the core principles and best practices for implementing DataOps. As well as emphasizes continuous integration, testing, and deployment.
Here are another two ideas on how to collate your work with data.
Key principles of DataOps explained
Automation
Key repetitive tasks in data pipelines should and even must be automated. Otherwise you deprive yourself of efficiency and error reduction. Automated data extraction, transformation, and loading (ETL) processes save time and ensure data consistency. It also frees up data engineers for higher-value activities and enhances data pipeline consistency and reliability.
Take a look at Apache Airflow or Prefect: they enable automation and scheduling of data workflows, making them easier to manage.
Learn more about automation for data engineering teams
Continuous integration and delivery (CI/CD)
CI/CD practices in DataOps streamline the development, testing, and deployment of data pipelines. By integrating continuous testing and delivery, teams can ensure that changes are quickly and reliably incorporated into production. This approach minimizes downtime and accelerates the delivery of data insights.
Infrastructure as Code (IaC)
IaC allows teams to manage data infrastructure using code, ensuring consistency and scalability. Some of the top-of-mind tools are Terraform and AWS CloudFormation. They help define infrastructure in code and enable version control while simplifying deployments across multiple environments. This practice supports agile development and enhances collaboration among teams.
Monitoring and observability
Proactive monitoring and observability are essential for maintaining the health and performance of data pipelines. Not a recommendation, but implementing Prometheus or Grafana allows teams to track metrics, log data, and set up alerts for potential issues. This way, they will get detailed visibility so that they will be able to quickly identify and resolve problems.
Unlocking the benefits of DataOps
Improved data quality
DataOps significantly enhances data quality by automating and monitoring data processes. Repetitive tasks like data transformation are completed without human participation, reducing the risk of human error. Additionally, proactive monitoring allows for early detection and resolution of data quality issues before they impact downstream analytics.
Imagine a data pipeline free of inconsistencies and errors — a reliable foundation for data-driven decision-making. That is exactly what you can get with data ops.
Enhanced collaboration
DataOps breaks down communication gaps and creates a single environment where data engineers, scientists, and analysts work together without any distractions. This collaboration lets data flow efficiently and meets the needs of all stakeholders. Consequently, communication and knowledge-sharing become central to success.
Faster time-to-insights
Streamlined workflows and automation accelerate data delivery and insight generation. After implementing DataOps principles, Capital One reduced its data processing time by a significant percentage, enabling it to make faster and more data-driven decisions.
This is not to mention regulatory issues. In the financial industry, they are paramount. And this is where DataOps practices come into play for Capital One. They ensure that data handling and processing meet strict regulatory standards, protecting customer information, maintaining trust and increasing agility.
DataOps enables rapid adaptation to changing business needs and data requirements. Its flexible framework allows teams to quickly adjust data processes in response to new challenges or opportunities. This agility helps businesses stay competitive and responsive in a dynamic market.
Reduced costs
Automation in DataOps can significantly cut down operational costs associated with manual data management. Gartner states companies that adopt automation in their data processes can reduce costs by up to 40%.
However, about 87% of companies in the US now have a low-maturity level of data management. Yet, this reduction in costs, which came from decreased manual effort and increased efficiency, is worth trying DataOps.
How DataOps works in practice
Brief follow-up: DataOps is an approach to managing a company’s data that emphasizes both flexibility and control. It promotes collaboration between developers and stakeholders, allowing for quick response to user needs while adhering to governance principles such as change control, accountability, data quality, and security.
Unfortunately, big enterprises are used to a rigid plan-first, develop-later approach (the waterfall method). Instead, DataOps involves making changes to data products and platforms throughout the development process based on continuous feedback from stakeholders and automated testing. Consequently, the company gets faster development and lower costs, while ensuring user satisfaction and compliance with governance standards.
Learning any topic is quite better on examples. Imagine a company aiming to improve customer retention by predicting customer churn. Traditionally, this workflow involves manual data collection, cleaning, and analysis, which can be time-consuming and error-prone. Not with DataOps.
Let’s transform this process by automating and streamlining each step.
Data management scheme of renowned business analyst and author Wayne Eckerson
Data collection and integration: Data engineers set up automated data pipelines to collect data from various sources such as CRM systems, transaction logs, and customer service records. We’ve already mentioned raiders for this reason: Apache Airflow or Talend. Automate these tasks with them to ease off the process.
Data cleaning and transformation: Once collected, the data needs to be cleaned and transformed. Automated scripts and tools handle tasks like removing duplicates, filling missing values, and normalizing data formats. This ensures that the data is ready for analysis.
Model building and training: Data scientists then use this clean data to build and train predictive models. With DataOps, this process is streamlined through continuous integration and delivery (CI/CD) practices. Models are continuously tested and validated to ensure accuracy and reliability.
Insight generation: The time is ripe — data analysts use the output from these models to generate insights. This is where up-to-date predictions and trends come to dashboards and reports.
Collaboration through automated pipelines and feedback loops
Inside the DataOps approach, different data pros work together seamlessly through automated data pipelines. They receive continuous feedback and this way, ensures ongoing teamwork. For instance, if data analysts notice discrepancies in the predictions, they can quickly communicate with data scientists. The data scientists can then tweak the models, and data engineers can adjust the data pipelines accordingly.
3-step collaboration guide:
1. Automated pipelines: Set up robust pipelines to handle data flow.
2. Continuous feedback: Implement regular check-ins and updates.
3. Shared tools: Use common platforms and tools to facilitate teamwork.
To sum it up
Traditional data management approaches often struggle with siloed teams, inconsistent data quality, and slow delivery of insights. DataOps is a genuine game-changer.
What are data operations? They are principles for data management, streamlining processes and enhancing collaboration.
The DataOps framework opens the doors to organizations so that they can automate repetitive tasks, ensure data quality, and implement continuous integration and delivery (CI/CD). Additionally, proactive monitoring ensures data quality, while a focus on collaboration fosters knowledge sharing between data engineers, data scientists, and data analysts.
Consequently, companies get improved data quality, faster time-to-insights, and increased agility empowering businesses to make data-driven decisions with greater confidence. If you want to build a data-driven culture within your company, your data operations teams must embrace new approaches for working with information.
Make your data reliable now